March 28, 2014
Plastic trash

It is rare that architecture manages to make me angry, but here is a design that succeeds: Sung Jin Cho's Seawer: The Garbage-Seascraper. This won a honourable mention in Evolo's 2014 Skyscraper Competition. I assume it won it for nice design (it is indeed nifty looking) and being green.
The catch is that it fails to solve the problem it claims to solve.
The official motivation is that there is too much garbage in the ocean, forming things like the Great Pacific Garbage Patch. Enormous amount of non-biodegradable plastic (6 times the plankton biomass, apparently) causing damage to the ecosystem. It would be good if it could be removed somehow.
Unfortunately the proposed solution is a floating skyscraper that filters the seawater using baleen filters. Leaving economics and practicality aside, I think the design could work (it is not too different from a Salter sink). But filtering away all plastic will also filter away all the plankton: anything that is effective at removing plastic will also remove the wildlife.
The design claims it could remove 50,000 tons of garbage per year, cleaning 100,000 square km per year. Assuming the patch size mentioned in the proposal (1,392,482 square km) that would require a Seawer to filter for 14 years in order to clean the patch. This might actually be slow enough to allow the wildlife to recover from losing 7% each year. Assuming only one Seawer is used, of course.
The fundamental problem here, and the reason I got annoyed, is that this is exactly the same thing as I ranted about back in 2010: "But this doesn't matter much to the proposer, since the main point seems to be to make a cool, green project rather than solving the problem. I have earlier ranted a bit about how many designers love to come up with green designs that will never have the least environmental impact but provide them with social gratification."
Indeed, the imagery is the same: pictures hinting at floating fridges and furniture at a density one could walk on (rather than fine confetti in the water column), then a beautiful project that turns it all into blue water. That the project is unlikely to ever be built does not really matter - after all, it was part of a blue sky design contest giving kudos to its originator. But the end result is a non-solution reinforcing an erroneous understanding of what the situation is.
I still like the design. But I wish this creativity had either been used to solve a real problem well, or just created something lifting our spirits.
March 20, 2014
Rebecca's Evil Twin
It is interesting to see how journalists copying each other produce misinformation.
A while ago Rebecca Roache (and me, but she is the star and lead author on our paper) was interviewed in Aeon about enhancement and punishment. She got plenty of space to explain the tricky interplay between feelings of revenge, ethical theories of just punishment, how law enforcement actually works, and how future technology could complicate things. (It all began in this Practical Ethics post and has now led to some talks - and an upcoming paper, we promise!)
As soon as Aeon showed up the story was reported by the Daily Mail, immediately turned senastionalist: "Could we condemn criminals to suffer for hundreds of years? Biotechnology could let us extend convicts' lives 'indefinitely'". I assume the readers of the DM might feel this is a bit too wussy still.
Then the Telegraph turned it into "Prisoners 'could serve 1,000 year sentence in eight hours'" - now it is not just life extension, but superspeed drugs.
And then Slashdot reports "Time Dilation Drug Could Let Heinous Criminals Serve 1,000 Year Sentences" - by now the drug seems like an almost real thing, 1,000 year sentences are apparently a good thing, and the readers of Slashdot now think poor Rebecca is a nasty psychopath for promoting such a thing. Sigh.
If this was just a cascade of credulous media outlets copying each other I would not be that concerned - annoying, but a bit like agonizing over YouTube comments. However, the coverage also led to a post on Practical Ethics by Luke Davies taking Rebecca to task for her approval of these technologies. Except that most of this post of course builds on the distorted versions of what she actually said. The great irony is that he is now doing many of the arguments we have in our paper... and commenters are further outraged by the ruthless retributionist Rebecca. I am annoyed that the stupidity now has come home to our office again.
This is a sign we need to improve the epistemic systems of our society so noise does not overwhelm signal. Every step of filtering introduces bias, and as stories are rapidly bounced through a series of media they quickly become strongly distorted (image). And if a few hot buttons get pressed, the result gets even crazier (see this and this!)
A simple rule: before you comment or write an article about anything, check out the original source. People who just respond to a summary are filling our heads with filth, and should be treated with the same disdain as people who spit on the floor.
March 13, 2014
Simulating the arrival of emulations
A small working paper about when to expect brain emulations: Monte Carlo model of brain emulation development
The model is simple, but produces a some useful predictions. The main one is not where the peak is - sure, everybody will quote me on it, but it is fairly dependent on your assumptions about the brain. Similarly the probability of failing to ever get WBE because computing power falls short depends a lot on brain assumptions and what Moore's law scenario one gets.
What I think is important is that we can go from a world where WBE has a very low chance of happening to a world with a high chance in just 20 years. If we get WBE from a breakthrough in scanning or neuroscience rather than hardware improvements allowing us to scale up small animal brain simulations, then there is room for an impressive overshoot where a lot of copies or very fast emulations become suddenly possible.
Perhaps most important is that different viewers can insert their own assumptions into the model and explore their consequences. We can update it as new data arrives, and get scenario distributions for the future. That will help us figure out where we are in relation to the emergence of WBE.
March 09, 2014
Are superstars good? Fame vs. merit
Yesterday I looked at fame distributions and their inequality, concluding that they are very unequal. But maybe merit is just as unequally distributed too? After all, Norman Borlaug saved hundreds of million of lives, while most of us can hardly claim to have saved even a single one. So I wanted to see if a reputation system could track actual merit, or the rich-get-richer aspects of being well-known would swamp it.
My model is as follows: people arrive to a group, selecting 5 people to adore. Each person has a merit that is distributed as a x-2 power law, and a fame corresponding to the number of people adoring them. The new people select targets with a probability proportional to a weighed combination of their normalized apparent merit plus their normalized fame: how much they weigh merit over fame is one of the parameters of the model. The apparent merit is the real merit combined with random noise; the amount of noise is the other parameter.
Since each new person can only choose from earlier persons, there will be some bias towards the first-comers even if they have low merit. In the case of not caring about merit at all it is just a preferential attachment process where we get celebrities famous for being famous.
Running it for a 1000 person population, repeating 10 times and plotting the average correlation between log(merit) and log(fame) for everyone (logarithms since these things range over several orders of magnitude) we get the following effect:
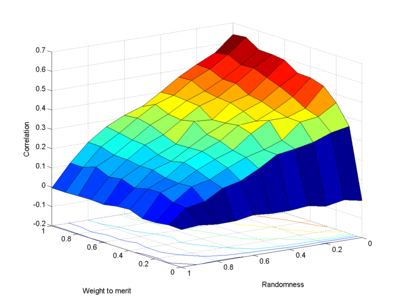
Most obviously, as the randomness decreases from left to right, the ability of the people to discern who has merit or not improves. Total noise (randomness=1) produces zero correlation between them. Similarly improving weighting of merit improves discernment - zero weight also produces populations with celebrities of random merit. As they weight merit more, merit and reputation become more correlated.
But even for zero noise and everybody basing their choice solely on merit, the correlation only becomes 0.7. Superstars may not be mediocre, but there is no guarantee they are the best, as can be seen below. Some diamonds are still hidden in the rough, and the best person is not the most well-known.
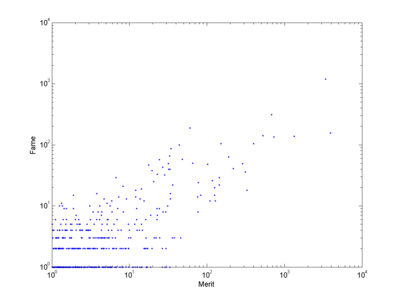
One could argue that this is because people in my model select people to adore stupidly. They just select people with a probability proportional to actual merit, not just the top 5 people. But in real life we rarely spend time finding the best target of our admiration - we have limited time, attention and information and hence will make choices from smaller sets of candidates than we should (after all, how many have heard about the scientists greater than Einstein?) So I think my simple model gets things roughly right: limited agents will not achieve a perfect match between reputation and merit, even when they are unbiased by celebrity and noise. And the real world case is likely far worse.
So reputation economies will not be able to achieve a strong match between reputation and actual merit. They can achieve correlation, but one can argue this is true for current economies too (I tend to sell more if I make stuff that people like rather than stuff they hate). The argument that capitalism distorts this because you can make more by investing rather than being good obviously applies to reputations too: if you are well-known, you can more easily get people to notice your latest good deed. The nature of attention simply tends to bias us towards a few superstars.
March 08, 2014
The reputation 1%
Yesterday over dinner, while discussing alternative monetary systems, reputation economy came up. While most discussions centre on using on-line reputations to stabilize virtual social structures or reduce transaction friction (often as a enabler of sharing systems), others wonder if one could not go all the way to Doctorow's Whuffie. In a post-scarcity economy, why not make social capital your real capital? The idea is used to good effect in the Eclipse Phase (see Reputation and Social Networks for more game details). There is something intuitively appealing in the idea that your social merit determines what resources you get and how big projects you can undertake: people who do good things for others ought to be rewarded.
Still, appealing-sounding economic ideas have frequently had serious flaws. One issue is distribution: many proponents of reputation economies are egalitarians who think very unequal distributions of wealth are inherently bad (even if everybody came to their wealth through honest means). Would a reputation economy be more equal?
The nature of a reputation
A reputation in general can be seen as 'the beliefs or opinions that are generally held about someone or something'. It is a social evaluation not done by just one person, but by the network of people interacting or opining about the target. It is generally not a mere number, but have evaluative elements (some of us are infamous, and you can be known as unreliable yet entertaining). In short, real reputations are 'thick' concepts that are more like micro-biographies or association clouds linked to the person: they are not at all like a single number or rating.
It is not obvious how to replace money (scalar, fungible, well defined value) with something as rich as reputations. It would be like replacing coins with individual artworks.
However, simple scalar reputation ratings are easy to handle, so most digital systems compress reputations into shorthand numbers. Research Gate gives me a RG score of 20.65 for the moment, based mainly on the papers I have uploaded but also on how much I interact usefully with other researchers (of course implicitly rewarding people who do much within RG over people who do stuff elsewhere). Some academics spend far too much time worrying about their citation indices, which again are widely recognized as misleading and too limited - but if important decisions like tenure decisions are based on them, even a pointless number matters. So it is not too hard to imagine some kind of scalar reputation measure being developed, perhaps calculated from richer social data.
In practice, the data seems to split into attention and evaluations. The more people know about you, the bigger your reputation. The more people like you, the more positive evaluations. However, while very critical people are likely to voice disagreements and negative evaluations, most people who don't care for you will stay silent or not not interact, and friends and admirers are likely to leave positive signals. In fact, most current sites (with the exception of Reddit) only have upvotes. Hence the total amount of positive evaluation is likely proportional to attention: he who is known by most will also have the highest reputation. It might be a mixed reputation, but unknown people are unlikely to get very high or low evaluation scores.
The distribution of fame
So, to a first approximation, we should expect reputations to be distributed like how well-known somebody is. Basically, reputation equals fame.
The distribution of fame has been investigated a fair bit.
Blogs can be studied in terms of how many links they get, which is a plausible measure of how many read and react to them. Henry Farrell and Daniel W. Drezner 2008 found that the links were lognormally distributed. In general it is taken as a stylized fact that the link distribution is power-law distributed (e.g. Weblogs and power laws), perhaps with a stricter power law distribution in domains with stronger competition.
Eric Schulman has written a series of papers for the Annals of Improbable Research about estimating fame using web hits: 1999, 2001, 2006, 2009. While intended slightly tounge-in-cheek the findings are consistent with other studies. Most importantly, the number of references to a person can range over many orders of magnitude: the distribution of attention to people is clearly very skew.
Looking at references to scientists in books, a similarly skew distribution emerges: Science Hall of Fame. The distribution appears to be slightly lighter than a power-law (see diagram at the bottom), but the general heavy tail property remains.
M.V. Simkin and V.P. Roychowdhury examine the amount of writing and google hits about pilot aces, finding that fame grows exponentially with achievement (here measured in number of kills). They build a mathematical theory of fame, where they argue that 'the number of people with a particular level of achievement decreases exponentially with the level, leading to a power-law distribution of fame'.
Bagrow et al. argued for a linear relationship between fame and merit, based on number of papers published. But Simkin and Roychowdhury pointed out that the number of publications is not really a measure of merit, just productivity (which might be naturally lognormal). Number of citations are likely a better measure.
However, Bagrow et al. note that scientists may also be more known within small fields rather than across the whole public: reputations may not carry that far. In a more recent study Bagrow et al. find that scientists, fighter aces, actors, fictional villains, runners, programmers, and students have google mentions distributed with skew enough distributions that a power law cannot be excluded. This paper is interesting because it includes non-famous people (the students): the heavy tail of attention seems to be universal.
See also table 2 of Kunegis & Preusse 2012 for a long list of empirical skewness distributions.
So, to sum up: the amount of references to people, presumably a good measure of the attention and fame they receive, has a tail distribution that is at least as heavy as a lognormal distribution. There is some linear or nonlinear relation to merit, at least in the cases where merit is defineable, but it is likely very domain dependent.
The inequality of fame
If we for simplicity assume fame is distributed as a power law P(F) = F-a (a>0, F>=1), how unequally distributed is it?
We can calculate the Gini coefficient G=1/(2a-1). Power-law distributions with high a are more equal, as measured by the Gini coefficient.
The median fame grows as 21/(a-1) (Newman 2004). It descends from a singularity at a=1 to a median fame of 2 for a=2 and 1.41 for a=3: 50% of people have less fame than this. But the fraction of total fame (wealth in a reputation economy) in the more famous half is 2-(a-2)/(a-1) (if a>2). For a just above 2 the fraction is huge: a=2.1 gives 94% to the top half of the population. For a=3, 70% belongs there, and one needs to go up to a=4.8 to get it down to 60%. Indeed, the most famous 1% have 10% of all the fame in the a=3 case... and 65% in the a=2.1 case. For a less than or equal to 2 the single most famous individual will have a significant fraction of the entire fame of the society.
What is the fame distribution exponent? The power-law fits of Bagrow and ben-Avraham give a in the range 1.77 to 2.69 for scientists, 2.74-3.62 for aces, 1.88-2.10 for actors, 1.57-2.03 for villains, 1.88-2.43 for programmers, 1.71-1.92 for runners, and 1.74-2.57 for students.
The American income distribution is roughly a=2.1. So fame is just as unequally distributed as income. In some populations it might even be way more unequal!
Discussion
Maybe this not a problem for a reputation economy. If we think fame is a honest indicator of merit (leaving aside infamy) then a very unequal distribution of fame might just mean an unequal distribution of merit. Some people just are nicer, more constructive or more ingenious than others. Maybe they should be given a large chunk of the total economy to play with.
If we think fame is at most a crude measure of merit, then these results become more problematic. It is not hard to build models of fame based on preferential attachment (you are more likely to hear about famous people than unknown people) or even limited memory capacity. Here fame does not track merit, and who ends up getting most of the attention cake may have very little to do with how good they are.
An idealist may argue that this is the fault of current reputation systems: first, they are one-dimensional and leave out important qualities, and second, a future reputation system may tie reputation to actual social merit rather than extraneous factors. Then a reputation currency would make sense and would be properly egalitarian (or at least merit based). I am somewhat pessimistic about this.
Non-scalar reputations are hard to compare, and people will likely want easy methods of allocation. Since deciding whether to do a trade or give something is binary, there is going to be some kind of personal decision boundary based on the reputation information. Insofar people have similar views of what makes a good reputation - remember that this is a social evaluation - their decisions boundaries are going to be correlated. So while I may care more about your reputation for rationality than my neighbour does, our decision to give you a gigabit of bandwidth are likely to be similar since we also weigh in your overall reputation for honesty, good computer security, reciprocity, being a god-fearing Dawkinite or what else is valued in our community. (The community-subjective aspects of reputations are of course another can of worms - reputation currencies might serve to enforce bad social ideals). In the end, reputations are going to be fairly one-dimensional since most parts of a good reputation are correlated or at least compensate for each other.
The second issue is probably even harder. Tying reputation to actual merit requires an objective evaluation that is hard to do, especially since social merit is something evaluated subjectively by people. But the subjective aspect means we get the usual very unequal fame dynamics again. The preferential attachment model suggests that someone doing something noticeably good (or bad) is likely to attract a nonlinear amount of attention: the total change in reputation is not going to be proportional to the good or bad done. A system that gives you an exponential reward for being nice sounds good at first, but since your reputation is always compared to the total reputation of the society that nonlinearity just leads to a winner-take all dynamics - especially if you get more attention for having more reputation. And conversely, somehow dampening the reputation reward for a good deed (improving equality) makes extremely good deeds requiring some work less appealing than doing smaller easy good deeds: the total amount of social utility produced would go down.
Maybe these problems can be solved. But we should recognize that money, for all its faults, doesn't discriminate about who you are. Reputations are always tied to who and what you are, who you associate with, and what others think about it. People who are bad at navigating the social space around them will be at a disadvantage in a reputation economy, while the charming butterflies will be rewarded. Maybe that is something we would enjoy, but from an ethical standpoint it doesn't seem that different.
(Bill Gates has merely 90 times as many Google hits (229 on Bing) on his name as I have on mine, but is at least 2.3 million times richer. So in reputation-world we would be more equal... but he would still be way richer.)
March 05, 2014
For a better century
Centenarians epitomise our fears about growing old - Avi and me discuss why centenarians might not be role models for life extension. They have been lucky and are pretty vital for their age, but unfortunately they are still very frail. My 103 year old grandmother can certainly not fence like when she was in the olympics!
This is what we need to fix in ageing. Either slow the fundamental process down (hard!) or reduce the accumulation of damage (tricky, but less hard). Just treating symptoms may make life better, but not fundamentally better.
March 04, 2014
Cold equations and trolleys
The cold equations of ethics - a little discussion of Doctorow's criticism of some sf as teaching bad morality due to contrived contexts as applied to philosophy thought experiments.
Whitepaper about systemic risk of risk modelling
Here is our whitepaper about the systemic risk of modelling, the first official output of the FHI-Amlin project.
The first section is about what systemic risk is, and how people use the term - in finance, in ecology, in technology. The second section is about the "autopilot problem", how models lull us into false security. And the final section is about asymmetric error checking, how we accidentally introduce our biases into our models.
Here is a cheerful little film about the collaboration. After all, this is just the start.
March 03, 2014
Why I hate the rocket equation
MIRI interview with me about long-range space colonization
Just after giving it, I noticed that the Tsiolkovsky rocket equation might be the favourite physics equation of Randall Munroe of XKCD - we have very divergent tastes.
I dislike the equation because it places a huge and cumbersome limit on space travel. I don't mind the lightspeed limit or the other relativistic annoyances, but the rocket equation really makes travel hard. So it is not an aesthetic problem, nor that it isn't neat as a physics result, but simply because it stops me from doing what I want. At least until I get a orbital elevator, good mass driver, beam propulsion and/or magsail.