December 22, 2010
Gift ethics
 Is it the thought that counts? - a light-hearted discussion between Kant, Aristotle and Bentham about the best Christmas presents.
Is it the thought that counts? - a light-hearted discussion between Kant, Aristotle and Bentham about the best Christmas presents.
I didn't have the time and space to get into the Rawlsian aspects of gift wrapping, and whether Secret Santa would meet with Rawl's and Hobbes' approval. Or what Nietzschean Christmas gift-giving would involve.
December 21, 2010
Tron 2
Saw Tron 2. 28 years later Hollywood has managed to update the 1982 film to 1992. I look forward to 2038 when we will see Tron 3 depict the Internet. And in 2066 we might even see things like social media in Tron 4!
December 19, 2010
Trending topics 1800-2000
Google's n-gram viewer is great fun, allowing me to look for trends in word usage across the scanned books.
Here is the spread of the terms 'transhuman' and 'posthuman':
![]()
Here are how different small prefixes are changing:
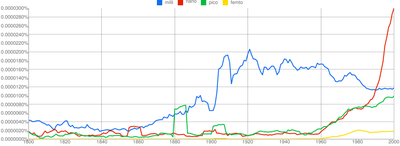
(I excluded micro- because it is much more common than the other ones)
And here is Plato vs. Aristotle vs. Rand.
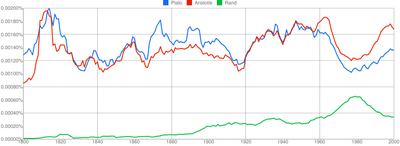
Anticorrelation or coincidence?
December 15, 2010
Some wintery intelligence?
 A little advert:
A little advert:
Future of Humanity Institute - Winter Intelligence Conference.
We are organizing a conference/set of conferences 14-16th of January in Oxford around intelligence. Non-standard intelligence, the future of machine intelligence (and some unity of consciousness). This interdisciplinary meeting might be of interest to readers of this blog.
December 06, 2010
Christmas present of the year: mathematics!
 I think this is the first novelty gift that is described by a conference paper: The Theory behind TheoryMine. TheoryMine is a company that uses automatic theorem discovery and proof to generate new theorems, which customers can then buy the naming rights for.
I think this is the first novelty gift that is described by a conference paper: The Theory behind TheoryMine. TheoryMine is a company that uses automatic theorem discovery and proof to generate new theorems, which customers can then buy the naming rights for.
This might sound similar to buying naming rights for stars which is a con, since real astronomers explicitly do not use or acknowledge the registries of star-naming companies. However, there is no formal system for naming theorems. There have also been real cases of theorems being sold, including the well-known L'Hôpital's rule which was likely due to Johann Bernoulli. In fact, a lot of named theorems are not due to the person who gave their name to them. Hence it is not that odd that one could buy the right to name a newly computer generated theorem. The real challenge is to get enough people to use it so that the name sticks. Given that the TheoryMine works in the domain of recursive theories generated to be deliberately obscure, this might prove to be hard. I suspect the recipients of a nice theorem ought to prove a few other theorems in the theory, and then write a paper about them. Sounds like a good activity for the after-Christmas holidays.
In related news the bloggosphere is a-twitter with excitement of the discovery how this paper rediscovers the trapezoidal rule of numerical integration, with the author naming it after himself. The paper even has a good amount of citations.
Most commenters have laughed at how Diabetes Care appears to have failed peer review, and how medical people clearly don't know elementary numerical calculus. I'm not entirely convinced: the paper itself is inaccessible (even from my Oxford University account), so we might be reading too much into the abstract. Second, several of the citing papers correctly calls the method the trapezoidal rule and not "Tai's rule", so maybe the paper is not as bad or self-serving as it looks. A lot of ridicule might have been avoided if it had been open publishing.
However, sometimes bringing a method that is well-known in one field into another field has very positive effects. Neural networks benefited greatly in the 1980's by being able to borrow methods from spin glass theory in physics. Physics benefited a lot from group theory once the link between particle symmetries and mathematical symmetries became clear. A friend of mine boasts that he got a paper out of the cross product, which neatly solved a problem in chemistry. So maybe telling diabetes researchers about the trapezoidal rule is worth a well-cited publication.
A final idea: Christmas present of the year: home-made theorems! Sure, you can buy a machine-made theorem. But why not try your hand at proving something nice for your loved one's? A neat geometrical construction for the kids to ponder, some topology for your aunt, some category theory about symmetric relations for your partner...
[Update: I have an extended version of this post here, on Practical Ethics: Is mathematics the Christmas present of the year? ]
December 02, 2010
Conspiring against the conspiracies
 State and Terrorist Conspiracies by Julian Assange (PDF, via zunguzungu) makes an interesting and in retrospect somewhat obvious point:
State and Terrorist Conspiracies by Julian Assange (PDF, via zunguzungu) makes an interesting and in retrospect somewhat obvious point:
Conspiracies are cognitive devices. They are able to out think the same group of individuals acting alone Conspiracies take information about the world in which they operate (the conspiratorial environment), pass it around the conspirators and then act on the result. We can see conspiracies as a type of device that has inputs (information about the environment) and outputs (actions intending to change or maintain the environment).
In short, conspiracies are a kind of collective intelligence enhancement.
His network model of conspiracies certainly fit in with our times (everything is a network, social or not, these days) but it is not clear that his model of conspiratorial power as the sum of graph weights actually has much meaning. A conspiracy with an infeasible goal (let's summon Cthulhu to destroy the world!) might have very strong internal links and plenty of coordination, yet its actual power is minimal. Similarly a conspiracy with faulty cognitive structure doesn't benefit from the coordination possibilities - if the old guard systematically ignore certain disconfirming information it might not matter if the agents produce enormous amounts of important input, since it will not help compute the next action. Real conspiratorial power is likely problem dependent: a Luttwakian coup d'Etat requires not just conspiratorial coordination but also command power over certain key assets, while implementing a propaganda strategy requires a different set of assets and coordination structures, and the same conspiracy might have vastly different power in these cases.
Assange argues that traditional attacks on nodes or links are not very effective (they are after all often hidden and the network might be resilient), while conspiracies have been empowered by literacy and the communications revolution. However, this misses the counterconspiracy effect: it has become easier to set up conspiracies of all kinds for most people. This means that the environment the conspiracy has to act in also becomes more complex: it is not just a risk of disclosure (which triggers resistance and is Assange's main point, of course) but there are going to be hidden networks acting counter to the conspiracy's goals that are hard to identify and handle. While the conspiracy of the powerful against the less powerful has an advantage it might not be as big as it once could have been. Part of it is the effect of transparency he discusses ("in a world where leaking is easy, secretive or unjust systems are nonlinearly hit relative to open, just systems."), but part of it is just that the world got even harder to control.
An interesting question is whether a more transparent society necessarily becomes safer from conspiracies. The noise level might go up so that only networks that are able to see through enough of the noise will be able to act effectively. It is not clear that transparency fixes authoritarian conspiracy if it gets lost in the noise.
I am reminded by Heylighen's paper Complexity and Information Overload in Society: why increasing efficiency leads to decreasing control. We are seeing a kind of race between information overload and amplified intelligence, but actions that amplify intelligence increase overload. One reason authoritarian governments and other groups like to control information might simply be to retain their control ability: as long as there is little information they have the best collective enhancement (they think), but with more open information everybody is essentially on the same level. The scary possibility is that people might invent better conspiracies that work at higher noise levels: such conspiracies might retain the authoritarian advantage while keeping everybody else trapped in the noise.
December 01, 2010
How are the big fallen?
I recently discussed with a colleague whether large organisations were more or less brittle than small ones. I decided to check using the Fortune 500 dataset; here are some preliminary findings.
Generally the profits and revenues grow exponentially over time, so I will be looking at list rankings. Plotting them since 1955 we get the following picture:
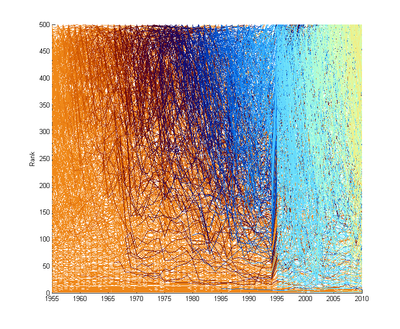
Color denotes the year when the company appeared, low rankings are big companies. A few things are clear: there seems to be more turbulence for smaller companies than big. Something happened 1995, and I currently do not know what it is: I suspect it is an artefact, and I need to control for it. A few years later Fortune began Forune 1000, so some companies can get rankings 500-1000 (not shown).
If we define a volatility measure as the sum of how many ranks companies that change rank after a year shift we get the following interesting plot of the average shift into or from different ranks (they differ because companies also appear and disappear):
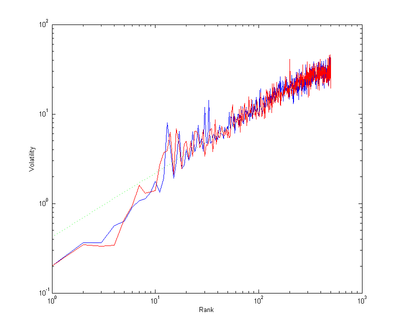
The green line corresponds to the power law r0.7 - smaller companies are more volatile than bigger ones, but the relation is somewhat convex.
Let's plot the rank trajectories around the year the company had their best rank yet disappeared from the list before 2010 (ignoring companies with less than 20 years of data for clarity - but also a possibly biasing assumption):
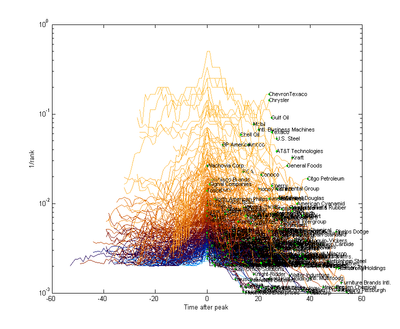
The green dots are the last year of the company on the list. It is worth noting that many "disappearing" companies actually were bought up or changed into other companies, so they certainly did not all go bankrupt. Another thing to actually take into account for a proper treatment.
The graph looks pretty symmetric. Plotting the same data as an imagemap where each row is a company, sorted after biggest rank, makes this more clear:
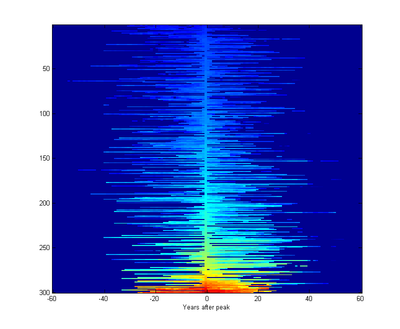
There doesn't seem to be much of a trend for big companies to last much longer than small companies, at least among companies with some history.
So my preliminary conclusion - with plenty of caveats due to the rawness of the data and some filtering effects - is that big companies disappear from Fortune 500 in the same way as small ones.