October 29, 2010
Finding Fermi
 Inviting invasion: deep space advertisments and planetary security (Practical Ethics) - I blog about the ethics of sending adverts into space. Basically, I don't think they make things better or worse.
Inviting invasion: deep space advertisments and planetary security (Practical Ethics) - I blog about the ethics of sending adverts into space. Basically, I don't think they make things better or worse.
I did not have the space in the article to list my full list of the Fermi paradox "solutions", but here they are:
- Aliens exist, but we see no evidence
- Human limitations
- Human beings have not been searching long enough (Freitas Jr 1983; Freitas Jr. 1985)
- Human beings are not listening properly
- Practical limitations
- Communication is impossible due to problems of scale
- Intelligent civilizations are too far apart in space or time (Wesson 1990)
- Communication is impossible for technical reasons
- They only recently emerged and have not yet had the time to become visible. This could for example be due to synchronization due to a declining rate of gamma ray bursts that sterilize much of the galaxy (Annis 1999; Cirkovic 2004).
- Civilizations only broadcast detectable radio signals for a brief period of time before moving on to other media.
- It is too expensive to spread physically throughout the galaxy (Landis 1998)
- Alien nature
- They are too alien to be recognized
- They are non-technological and cannot be detected except by visiting them.
- They tend to experience a technological singularity becoming unfathomable and invisible.
- They develop into very fast, information-dense states that have no reason to interact with humans (Smart 2002; Cirkovic and Bradbury 2006)
- They migrate away from the galactic disk for cooling reasons (Cirkovic and Bradbury 2006)
- They tend to (d)evolve to a post-intelligent state (Schroeder 2002)
- They choose not to interact with us
- They are here unobserved
- Earth is purposely isolated (The Zoo or "Interdict" hypotheseis) (Ball 1973; Fogg 1987)
- Earth (and nearby parts of space) are simulated (Baxter 2001; Bostrom 2003).
- They secretly deal with the government or other groups.
- Human limitations
- No other civilizations currently exist
- We are the lucky first civilization
- Intelligent, technological life is exceedingly rare
- Rare earth hypothesis
- Life is very rare (Wesson 1990)
- Intelligence is very rare
- Intelligent, technological life is very short-lived
- Intelligent life is wiped out by external disasters at a high rate
- Technological intelligent life exhaust its resources and dies out or becomes nontechnological
- It is the nature of intelligent life to destroy itself.
- It is the nature of intelligent life to destroy others.
Most of these are problematic because they assume uniformity of motive: every member of every civilization needs to agree to behave the same way. Given that new data on the age of Earth relative to other planets in the galaxy and better estimates of how life has evolved, it also becomes sharper. And almost whatever the answer is, it is going to tell us something significant about our own species future. Unless it is all about us using the wrong kinds of antennas.
October 28, 2010
Visions of the future in Milano
 I was at TransVision 2010 in Milano, meeting up with my fellow transhumanists. Giulio Prisco was of course the cornerstone, organizing everything. In principle the conference occurred simultaneously in meatspace and teleplace (despite occasional glitches - this was the first time I felt *I* got disconnected when the internet connection went down, rather than the virtual part of the conference being disconnected: a good sign!) Some of the videos are becoming available
I was at TransVision 2010 in Milano, meeting up with my fellow transhumanists. Giulio Prisco was of course the cornerstone, organizing everything. In principle the conference occurred simultaneously in meatspace and teleplace (despite occasional glitches - this was the first time I felt *I* got disconnected when the internet connection went down, rather than the virtual part of the conference being disconnected: a good sign!) Some of the videos are becoming available
My own talk was about the thermodynamics of advanced civilizations. Basically my argument was:
- Civilizations are physical objects, and nearly any ultimate goal imply a need for computation, storing bits and resources (the basic physical eschatology assumption).
- The universe has a bunch of issues:
- The stelliferous era will just last a trillion year or so.
- Matter and black holes are likely unstable, so after a certain time there will not be any structure around to build stuff from. Dark matter doesn't seem to be structurable either.
- Accelerating expansion prevents us from reaching beyond a certain horizon about 15 gigalightyears away.
- It will also split the superclusters into independent "island universes" that will become unreachable from each other within around 120 billion years.
- It also causes horizon radiation ~10-29 K hot, which makes infinite computation impossible.
- Civilizations have certain limits of resources, expansion, processing and waste heat:
- We can still lay our hands on 5.96·1051 kg matter (with dark matter 2.98·1052 kg) within the horizon, and ~2·1045 kg (with DM ~1046 kg) if we settle for a supercluster.
- The lightspeed limitation is not enormously cumbersome, if we use self-replicating probes.
- The finite energy cost of erasing bits is the toughest bound. It forces us to pay for observing the world, formatting new memory and correct errors.
- Putting it all together we end up with the following scenario for maximal information processing:
- The age of expansion: interstellar and intergalactic expansion with self-replicating probes. It looks like one can enforce "squatters rights", so there is no strong reason to start exploiting upon arrival.
- The age of preservation: await sufficiently low temperatures. A halving of temperature doubles the amount of computation you can do. You only need a logarithmically increasing number of backups for indefinite survival. Since fusion will release ~1% of the mass-energy of matter but black hole conversion ~50%, it might not be relevant to turn off the stars unless you feel particularly negentropic.
- The age of harvest: Exploit available energy to produce maximal amount of computation. The slower the exploitation, the more processing can be done. This is largely limited by structure decay: you need to be finished before your protons decay. Exactly how much computation you can do depends on how large fraction of the universe you got, how much reversible computation you can do and the exact background temperature.
- This leads to some policy-relevant conclusions:
- Cosmic waste is a serious issue: the value of the future is enormous in terms of human lives, so postponing colonization or increasing existential risk carries enormous disutilities. However, in order to plan like this you need to have very low discount rates.
- There are plenty of coordination problems: burning cosmic commons, berserker probes, entropy pollution etc. The current era is the only chance of setting up game rules before dispersion and loss of causal contact.
- This model suggests a Fermi paradox answer: the aliens are out there, waiting. They already own most of the universe and we better be nice to them. Alternatively, if there is a phase transition situation where we are among the first, we really need to think about stable coordination and bargaining strategies.
Basically, this is the "green" approach to the universe. Minimal early impact while natural complex structures are emerging, then maximal use of the resources to produce more complexity before the built-in unsustainability of the universe dominates.
[ I was intrigued today to read the review of Penrose's latest book in Nature. He argues for a scale-free cosmology where the early and very late universe are essentially identical except for scale. It is cyclic in time, but each cycle is separated by a maximal entropy state, it seems. So that cosmology doesn't allow escape from the matter decay in our current era. Still a bit uncertain how he manages to reset the entropy, though.]
October 27, 2010
Lovely corn infographic
Rob Carlson participated in the Economist debate on whether computing is the most significant technology over the last century. He has an amazing infographic in that post showing the US corn crop yield as a function of time, as well as the US planted area. That diagram is IMHO one of the best environmentalist arguments for GM crops.
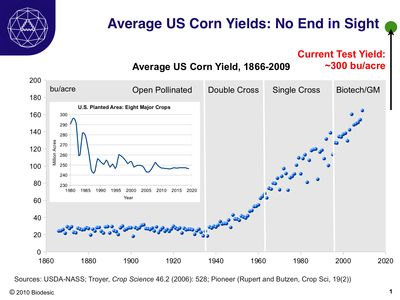
Thanks to crossing and ever more advanced biotechnologies yields have been increasing since the 1940s, yet still have plenty of room to go before reaching even current test limits. And the acreage needed has been declining, at least in principle allowing more space for nature.
Dreaming of aircraft carriers beyond the veil of ignorance
 My friend Stuart has two posts on Less Wrong, Let's split the cake, lengthwise, upwise and slantwise and If you don't know the name of the game, just tell me what I mean to you that bring up an interesting problem: how do we bargain in coordination games when we do not know exactly what the game will be beforehand? In games we know beforehand we can decide on how to go about things to make us all satisfied, but in situations where we will have iterated games of uncertain content bargaining gets complex. Stuart shows that one can do this by fixing a common relative measure of value and then maximize it, ignoring fairness considerations.
My friend Stuart has two posts on Less Wrong, Let's split the cake, lengthwise, upwise and slantwise and If you don't know the name of the game, just tell me what I mean to you that bring up an interesting problem: how do we bargain in coordination games when we do not know exactly what the game will be beforehand? In games we know beforehand we can decide on how to go about things to make us all satisfied, but in situations where we will have iterated games of uncertain content bargaining gets complex. Stuart shows that one can do this by fixing a common relative measure of value and then maximize it, ignoring fairness considerations.
This seems to be a different take on fairness from Rawls, who assumes that people beyond the veil of ignorance do not even know their conceptions of the good (utilities). However, then maybe the rational choice is just to select a random relative measure or use the Nash Bargaining solution or the Kalai-Smorodinsky Bargaining Solution with an arbitrary disagreement point.
However, this seems to be too arbitrary. Rational agents will know that as rational agents their utility functions will *not* be entirely random, but will tend to maximize certain coherent things in the world. So hence they would have some form of prior about their utility function even beyond the veil of ignorance based on them being rational agents, and this might help fix the initial bargaining agreement. However, in this case the priors for future utility functions will be identical, so it seems that bargaining would be simple: they will expect on average have similar utilities.
In the real world case of me and Stuart meeting and deciding how we will bargain in the future, we of course are helped by actually having utility functions *and* having priors for what games will be played.
October 26, 2010
Smart slackers
 Bryan Caplan speaks out Against High-IQ Misanthropy, the view that stupid people shouldn't have kids. He makes the point:
Bryan Caplan speaks out Against High-IQ Misanthropy, the view that stupid people shouldn't have kids. He makes the point:
Bottom line: When stupid people have kids, high-IQ people should be happy for them. Being smart is better than being stupid, but being stupid and alive is far better than not existing at all.
This is a moral argument, but he also has economic arguments. In an earlier post he points out that increasing the supply or demand for brains is a better strategy for getting more brains than trying to get some group to have fewer children.
In another previous posts he gives a nice argument for what is wrong with some eugenic arguments. It is not an argument against eugenics per se, but against the view that letting in stupid people into a smart society is bad: on the contrary, due to the law of comparative advantage it makes everybody better off since now the Einsteins can focus on what they are good at rather than taking out the trash. Note that this is not based on assuming that the Einstens dislike doing menial jobs: they can do both brain work and janitorial work, it is just that they are better at brain work than less brilliant people. Hence productivity will grow if people switch jobs.
Many seem to assume that smart people dislike doing simple work, but I think this is wrong. I met my first philosophy Ph.D. happily working as a postman. Smart people simply have many more possible jobs to choose from, so if they dislike their current job they can switch to something else. In fact, this leads to an argument for why we should want to enhance intelligence or even do eugenics: it might be unfair to the stupid people that they have fewer possibilities for job satisfaction.
He also points out "In a market economy, being less productive than average doesn't make you a parasite. If you produce less, you earn less - simple as that." However, in non-market economies it seems to me that low-productive members may become seen as parasites - it is hence better to be a slacker who could work hard but don't want to in a capitalist system than (say) in a socialist system.
October 11, 2010
Visualising the scientific state
 Information is Beautiful has one of the most promising visualisations about health I know of. Basically, it shows various nutritional supplements and how much scientific evidence there is for them to actually work asa cloud of bubbles. By clicking a filter one can see supplements against a certain condition and clicking on a bubble one can find abstracts about the supplement. It is pretty self-explanatory and gives good intuitive feel.
Information is Beautiful has one of the most promising visualisations about health I know of. Basically, it shows various nutritional supplements and how much scientific evidence there is for them to actually work asa cloud of bubbles. By clicking a filter one can see supplements against a certain condition and clicking on a bubble one can find abstracts about the supplement. It is pretty self-explanatory and gives good intuitive feel.
There are some problems of course. Size of the circles denotes popularity on the internet, which is distracting if you are more interested in what you should be considering to take than the extent of snake oil use. I would prefer to see something like number of studies or effect sizes instead. Maybe colour would be better used to denote popularity. Ideally the measure of effectiveness would be some automatically generated meta-study data, like an estimated effect size, but here there are likely different methods. I would probably have used some simple measure as default and then added an option for showing other data.
Generally speaking, what number of studies are needed to rationally decide to take a supplement (or eat/not eat a certain kind of food, use a technology etc?) Imagine that the real effect size is X. A study of size N will produce an estimated effect size of Y=X+e, where e is noise of amplitude ~k/sqrt(N) (where k is depending on how noisy this kind of study is). Let's assume no bias and that everything is Gaussian (in reality the file drawer problem will introduce bias). As more studies of size Ni and effect size Yi arrive, we can average them together to estimate X (in practice meta-analysis use more sophisticated statistical methods). The average of all data points would be distributed as N(Ymean, k^2/Ntotal)where Ymean is the weighted mean and Ntotal the total number of data points. If Ymeansqrt(Ntotal)/k is large then we ought to do something.
So, where does this leave us? First, it would obviously be useful to have a tool that collated all relevant studies and calculated things like the above number. In practice this is hard since many studies use different effect size measures, and to properly do meta-analysis you need to check other aspects of study quality.
But as a rule of thumb, if the claimed effect sizes are large when compiled in a meta-analysis you should sit up and take notice. Both because there might be something there, and because it actually matters - taking a nutritional supplement with a proven but minimal effect is a waste of effort.
The number of studies done gives some indication of how large Ntotal is. If we assume a field starts out with a few small studies and then moves to large studies, the quality of data should be expected to rise sharply only after a while (and then we just get a slow increase since the benefit of super-large studies gets counteracted by the convexity of the square root). A pilot study will have on the order of ~10-100 participants, while a big study will have ~1000+ participants - it will push the X estimate at 2 or 3 times more than the small study. So this leads to another heuristic: the longer a field has been gathering data, the more reliable it is. This is not just from the accumulation of studies, but also that dis-confirming evidence and new measurement methods will have arrived, increasing robustness. So if a modern meta-analysis agrees with older ones, then we have reason to think the conclusion is pretty reliable (or has gotten stuck in a dogma).
From a practical standpoint this is still pretty useless. I cannot easily call up all studies on the health benefits of cashew nuts, vitamin D or yoga and get their N, effect sizes and historical distribution compared... yet. I think that will change soon, and that may lead to a much stronger evidence base for a lot of things. Just being able to get funnel plots of studies would be helpful for seeing where things are leaning. Plenty of potential for misunderstanding and bias too - statistics is a subtle science, some biasing effects can be pretty insidious and many studies are about apples and oranges. But our ability to collate and visualize scientific data efficiently is increasing. The snake-oil visualisation is an early, promising step in bringing it to the public.
October 09, 2010
What did you learn about the singularity today?
 What did I learn about the singularity during our track at ECAP10? Anna Salamon pressed me into trying to answer this good question. First, an overview of the proceedings:
What did I learn about the singularity during our track at ECAP10? Anna Salamon pressed me into trying to answer this good question. First, an overview of the proceedings:
Defining the subject
Amnon Eden started out by trying to clear up the concepts, or at least show where concepts need to be cleared up. His list of central questions included:
- What is the singularity hypothesis? What is actually being claimed? This is really the first thing to be done, without clarifying the claim thee is no real subject.
- What is the empirical content of that claim? Can it be refuted or corroborated, and if so, how?
- What exactly is the nature of the event forecasted? A discontinuity a la a phase transition or a process like Toffler's waves?
- What - if anything - accelerates? Which metrics can be used to measure acceleration? What evidence supports its existence?
- Is Moore's law a law of nature? What about the law of accelerating returns? (after all, some people seem to think this, and if that were true it would indeed be a non-trivial result)
- What is actual likelihood of an intelligence explosion (or other runaway effect)? Can it be prevented?
- Has machine intelligence really been growing?
- What does it mean to claim that biological evolution will be replaced by technological evolution?
- How much can human intelligence increase?
- How different would posthuman or cyborg children be from us?
- What are the necessary and sufficient conditions for WBE? What must be emulated?
Conditions for the singularity
 Anna Salamon gave a talk on "How intelligible is intelligence?" The key question is whether there exists simple principles that could produce powerful optimizers that work on many domains and targets, and whether they are easy to figure out. This has obvious implications for the above questions, such as how likely sudden breakthroughs are compared to slow trial-and-error and complete failure (c.f. my and Carl's talk). While she did not have a precise and formal definition of intelligible concepts or things it is pretty intuitive: one can extend intelligible systems from principles or simpler versions, they are not domain specific, they can be implemented in many substrates, aliens would likely be able to come up with the concept. Unintelligible systems are just arbitrary accumulations of parts or everything-connected-to-everything jumbles.
Anna Salamon gave a talk on "How intelligible is intelligence?" The key question is whether there exists simple principles that could produce powerful optimizers that work on many domains and targets, and whether they are easy to figure out. This has obvious implications for the above questions, such as how likely sudden breakthroughs are compared to slow trial-and-error and complete failure (c.f. my and Carl's talk). While she did not have a precise and formal definition of intelligible concepts or things it is pretty intuitive: one can extend intelligible systems from principles or simpler versions, they are not domain specific, they can be implemented in many substrates, aliens would likely be able to come up with the concept. Unintelligible systems are just arbitrary accumulations of parts or everything-connected-to-everything jumbles.
Looking through evidence in theoretical computer science, real computer science, biology and human communities her conclusion was that intelligence is at least somewhat intelligible - it doesn't seem to rely just on accumulating domain-specific tricks, it seems to have a few general and likely relatively simple modules that are extendible. Overall, a good start. As she said, now we need to look at whether we can formally quantify the question and gather more evidence. It actually looks possible.
She made the point that many growth curves (in technology) look continuous rather than stair step-like, which suggests they are due to progress on unintelligible systems (an accumulation of many small hacks). It might also be that systems have an intelligibility spectrum: modules on different levels are differently difficult, and while there might be smooth progress on one level other levels might be resistant (for example, neurons are easier to figure out than cortical microcircuits). This again has bearing on the WBE problem: at what level does intelligibility, the ability to get the necessary data and having enough computer power intersect first? Depending on where, the result might be very different (Joscha Bach and me had a big discussion on whether 'generic brains'/brain-based AI (Joscha's view) or individual brains (my view) would be the first outcome of WBE, with professor Günther Palm arguing for brain-inspired AI).
Joscha Bach argued that there were four preconditions for reaching an AI singularity:
- Perceptual/cognitive access. The AIs need be able to sense and represent the environment, universal representations and general enough intelligence.
- Operational access. They need to be able to act upon the outside environment: they need write access, feedback, that they can reach critical environment and (in the case of self-improvement) access to their own substrate.
- Directed behaviour. They need to autonomously pursue behaviour that include reaching the singularity. This requires a motivational system or some functional equivalent, agency (directed behavior), autonomy (the ability to set own goals), and a tendency set goals that increase abilities and survivability.
- Resource sufficiency. There has to be enough resources for them to all this.
His key claim was that these functional requirements are orthogonal to architecture of actual implementations, and hence AI singularity is not automatically a consequence of having AI.
I think this claim is problematic: 1 (and maybe parts of 3) is essentially implied by any real progress in AI. But I think he clarified a set of important assumptions, and if all these preconditions are necessary it is enough that one of them is not met for an AI singularity not to happen. Refining this a bit further might be really useful.
He also made a very important point that is often overlooked: the threat/promise lies not in the implementation but is a functional one. We should worry about intelligent agents pursuing a non-human agenda that are self improving and self-extending. Many organisations come close. Just because they are composed of humans doesn't mean they work for the interest of those humans. I think he is right on the money that we should watch for the possibility of an organisational singularity, especially since AI or other technology might provide further enhancement of the preconditions above even when the AI itself is not enough to go singular.
Kaj Sotala talked about factors that give a system high "optimization power"/intelligence. Calling it optimization power has the benefit of discouraging anthropomorphizing, but it might miss some of the creative aspects of intelligence. He categorised them into: 1) Hardware advantages: faster serial processing, faster parallel processing, superior working memory equivalent. 2) Self improvement and architectural advantages: the ability to modify itself, overcome biased reasoning, algorithms for formally collect reasoning and adding new modules such as fully integrating complex models. 3) Software advantages: copyability, improved communication bandwidth, speed etc. Meanwhile humans have various handicaps, ranging from our clunky hardware to our tendency to model others by modelling on ourselves. So there are good reasons to think an artificial intelligence could achieve various optimization/intelligence advantages over humans relatively simply if it came into existence. Given the previous talk, his list is also interestingly functional rather than substrate-based. He concluded: "If you are building an AI, please be careful, please try to know what you are doing". Which nicely segues into the next pair of talks:
Will superintelligences behave morally or not?

Joshua Fox argued that superintelligence does not imply benevolence. We cannot easily extrapolate nice moral trends among humans or human societies to (self)constructed intelligences with different cognitive architectures. He argued that instrumental morality is not guaranteed: reputations, the powers to monitor, punish and reward each other, and the economic incentives to cooperate are not reliable arguments for proving the benevolence of this kind of agents. Axiological morality depends on what the good truly is. Kant would no doubt argue that any sufficiently smart rational mind will discover moral principles making it benevolent. But looking at AIXI (an existence proof of superintelligence) suggests that there is no "room" for benevolence as a built in terminal value - to get a benevolent AIXI you need to put it into the utility function you plug in. A non-benevolent AIXI will not become benevolent unless it suits its overall goal, and it will not change its utility function to become more benevolent since preservation of goals is a stable equilibrium. Simple goals are too simple to subsume human welfare, while overly complex goals are unlikely to be benevolent. Reflective equilibrium
He concluded that if dispositions can be modified and verified, then weak AI can credibly commit to benevolence. If benevolent terminal values are built in then the AI will fight to protect them. But if AI advances abruptly, and does not have built in beneficence from the start, then benevolence does not follow from intelligence. We need to learn benevolence engineering and apply it.
I personally think instrumental morality is more reliable and robust than Joshua gave it credit for (e.g. things like comparative advantage), but this of course needs more investigation and might be contingent on factors such as whether fast intelligence explosions produce intelligence distributions that are discontinuous. Overall, it all links back to the original question: are intelligence explosions fast and abrupt? If they aren't, then benevolence can likely be achieved (if we are lucky) through instrumental means, the presence of some AIs engineered to be benevolent and the "rearing" of AI within the present civilization. But if they are sharp, then benevolence engineering (a replacement for 'friendliness theory'?) becomes essential - yet there are no guarantees it will be applied to the first systems to really improve themselves.
Mark R. Waser had a different view. He claims superintelligence implies moral behavior. Basically he argues that the top goal we have is "we want what we want". All morality is instrumental to this, and human morality is simply imperfect because it has evolved from emotional rules of thumb. Humans have a disparity of goals, but reasonably consensus on the morality of most actions (then ethicists and other smart people come in a confuse us about why, gaining social benefits). Basically ethics is instrumental, and cooperation gives us what we want while not preventing others from getting what they want. The right application of game theory a la the iterated prisoner's dilemma leads to a universal consistent goal system, and this will be benevolent.
I think he crossed the is-ought line a few times here. Overall, it was based more on assertion than a strict argument, although I think it can be refined into one. It clearly shows that the AI friendliness problem is getting to the stage where professional ethicists would be helpful - the hubris of computer scientists is needed to push forward into these tough metaethical matters, but it would help if the arguments were refined by people who actually know what they are doing.
Intelligence explosion dynamics
 Stephen Kaas presented an endogenous growth model of the economic impact of AI. It was extremely minimal, just Romer's model with the assumption that beyond a certain technology level new physical capital also produces human capital (an AI or upload is after all physical capital that has 'human' capital). The result is a finite time singularity, of course. This is generic behaviour even when there are decreasing margins. The virtue of the model is that it is a minuscule extension of the standard model: no complex assumptions, just AI doing what it is supposed to do. Very neat.
Stephen Kaas presented an endogenous growth model of the economic impact of AI. It was extremely minimal, just Romer's model with the assumption that beyond a certain technology level new physical capital also produces human capital (an AI or upload is after all physical capital that has 'human' capital). The result is a finite time singularity, of course. This is generic behaviour even when there are decreasing margins. The virtue of the model is that it is a minuscule extension of the standard model: no complex assumptions, just AI doing what it is supposed to do. Very neat.
Carl Shulman and me gave a talk about hardware vs. software as the bottleneck for intelligence explosions. See previous posting for details. Basically we argued that if hardware is the limiting factor we should see earlier but softer intelligence explosions than if software is hard to do, in which case we should see later, less expected and harder takeoffs.
There is an interesting interaction between intelligibility and this dynamics. Non-intelligible intelligence requires a lot of research and experimentation, slowing down progress and requiring significant amounts of hardware: a late breakthrough but likely slower. If intelligence is intelligible it does not follow that it is easy to figure out: in this case a late sharp transition is likely. Easy intelligence on the other hand gives us an early soft hardware scenario. So maybe unintelligible intelligence is a way to get a late soft singularity, and evidence for it (such as signs that there are just lots of evolved modules rather than overarching neural principles) should be seen as somewhat reassuring.
Constructing the singularity?
 Scott Yim approached the whole subject from a future studies/sociology angle. According to "the central dogma of future studies" there is no future, we construct it. Many images of the future are a reaction to one's views on the uncertainty in life: it might be a rollercoaster - no control, moves in a deterministic manner (Kurzweil was mentioned), it might be like rafting - some control, a circumscribed path (Platt) or like sailing - ultimate control over where one is going (Ian Pearson).
Scott Yim approached the whole subject from a future studies/sociology angle. According to "the central dogma of future studies" there is no future, we construct it. Many images of the future are a reaction to one's views on the uncertainty in life: it might be a rollercoaster - no control, moves in a deterministic manner (Kurzweil was mentioned), it might be like rafting - some control, a circumscribed path (Platt) or like sailing - ultimate control over where one is going (Ian Pearson).
While the talk itself didn't have much content I think Scott was right in bringing up the issue: what do our singularity models tell us about ourselves? And what kind of constructions do they suggest? In many ways singularity studies is about the prophecy that the human condition can be radically transformed, taking it from the more narrow individualistic view of transhumanism (where individuals can get transformed) to look at how the whole human system gets transformed. It might be implicit in posing the whole concept that we think singularities are in a sense desirable, even though they are also risky, and that this should guide our actions.
I also think it is important for singularity studies to try to find policy implications of their results. Even if it was entirely non-normative the field should (in order to be relevant) bring us useful information about our options and their likely impact. Today most advice is of course mostly of the "more research is needed" type, but at least meetings like this show that we are beginning to figure out *where* this research would be extra important.
What did I learn?
The big thing was that it actually looks like one could create a field of "acceleration studies", dealing with Amnon's questions in a intellectually responsible manner. Previously we have seen plenty of handwaving, but some of that handwaving has now been distilled through internal debate and some helpful outside action to the stage where real hypotheses can be stated, evidence collected and models constructed. It is still a pre-paradigmatic field, which might be a great opportunity - we do not have any hardened consensus on How Things Are, and plenty of potentially useful disagreements.
Intelligibility seems to be a great target for study, together with a more general theory of how technological fields can progress. I got some ideas that are so good I will not write about them until I have tried to turn them into a paper (or blog post).
One minor realization was to recall Amdahl's law, which had really slipped my mind but seems quite relevant for updates of our paper. Overall, the taxonomies of preconditions and optimization power increases, as well as Carl's analysis of 'serial' versus 'parallel' parts of technology development, suggests that this kind of analysis could be extended to look for bottlenecks in singularities: they will at the very least be dominated by the least 'parallelisable' element of the system. Which might very well be humans in society-wide changes.
Sex, supporters and spurious statistics
 Here is a fun paper: Patrick M. Markey, Charlotte N. Markey, Changes in pornography-seeking behaviors following political elections: an examination of the challenge hypothesis, Evolution & Human Behavior - 28 September 2010 (found via Nonicoclolasos). The authors found that the number of web searches for pornography increased after the American elections in the states that voted for the winning candidate. Vicariously "winning" through a candidate might be similar to vicariously winning through sports teams, and there are studies that show that the supporters of the winning side get increased testosterone levels. Stanton SJ, Beehner JC, Saini EK, Kuhn CM, Labar KS. Dominance, politics, and physiology: voters' testosterone changes on the night of the 2008 United States presidential election. PLoS One. 2009 Oct 21;4(10):e7543. studied voters before and after Obama was elected, finding that male supporters of the losing candidate had decreases of testosterone levels (no effect in the females). There are of course stress hormone effects too, but they have been inconsistent.
Here is a fun paper: Patrick M. Markey, Charlotte N. Markey, Changes in pornography-seeking behaviors following political elections: an examination of the challenge hypothesis, Evolution & Human Behavior - 28 September 2010 (found via Nonicoclolasos). The authors found that the number of web searches for pornography increased after the American elections in the states that voted for the winning candidate. Vicariously "winning" through a candidate might be similar to vicariously winning through sports teams, and there are studies that show that the supporters of the winning side get increased testosterone levels. Stanton SJ, Beehner JC, Saini EK, Kuhn CM, Labar KS. Dominance, politics, and physiology: voters' testosterone changes on the night of the 2008 United States presidential election. PLoS One. 2009 Oct 21;4(10):e7543. studied voters before and after Obama was elected, finding that male supporters of the losing candidate had decreases of testosterone levels (no effect in the females). There are of course stress hormone effects too, but they have been inconsistent.
Apropos sex and sports, The Register has an interesting article about the mysterious 40,000 roving sex-workers that are supposed to descend on any major sports event. Basically, whenever there is a major event, the usual anti-prostitution suspects begin to warn about an imminent rise of prostitution and trafficking and demand that Something Must Be Done. Available evidence doesn't support it at all (and, as the article points out, the numbers seem to be entirely made up - and actually quite absurd) but that has never stopped the guardians of public morality on the left and right. Maybe they are convinced that the testosterone effects above are strong enough to drive an increased demand. But that assumes there are more winning than losing supporters.
October 07, 2010
Why early singularities are softer
 Carl Shulman from SIAI and me gave a talk yesterday at ECAP10: "Implications of a Software-limited Singularity". We give an argument for why - if the AI singularity happens - an early singularity is likely to be slower and more predictable than a late-occurring one.
Carl Shulman from SIAI and me gave a talk yesterday at ECAP10: "Implications of a Software-limited Singularity". We give an argument for why - if the AI singularity happens - an early singularity is likely to be slower and more predictable than a late-occurring one.
Here is the gist of our argument:
Some adherents to the singularity hypothesis (Hans Moravec, Ray Solomonoff and James Martin, for example) use variants of the following "hardware argument" to claim we will have one fairly soon:
- Moore's law will lead to cheap human-level CPUs by, e.g. 2040.
- Cheap human-level CPUs will lead to human-level AI within 30 years.
- Human-level AI will lead to an intelligence explosion.
Therefore,
- Intelligence explosion by 2070.

Premise 1 is pretty plausible (I was amazed by the optimism in the latest semiconductor roadmap). Premise 3 is moderately plausible (skilled AI can be copied and run fast, and humans have not evolved to be optimal for AI research). Premise 2 is what critics of the argument (Lanier, 2000; Hofstadter, 2008; Chalmers, 2010) usually attack: just having amazing hardware doesn't tell us how to use it to run an AI, and good hardware is not obviously going to lead to good software.
A sizeable part of our talk dealt with the evidence for hardware actually making AIs perform better. It turns out that in many domains the link is pretty weak, but not non-existent: better hardware does allow some amazing improvements in chess, text processing, computer vision, evolving new algorithms, using larger datasets and - through the growth of ICT - more clever people getting computer science degrees and inventing things. Still, software improvements often seems to allow bigger jumps in AI performance than hardware improvements. A billionfold in hardware capacity since 1970 and a 20-fold increase in the number of people in computer science has not led to an equally radical intelligence improvement.
This suggests that the real problem is that AI is limited by serial bottlenecks: in order to get AI we need algorithmic inventions, and these do not occur much faster now than in the past because they are very rare, requires insights or work efforts that doesn't scale with the number of researchers (10,000 people researching for one year likely cannot beat 1,000 people researching the same thing for ten years) and experiments must be designed and implemented (takes time, and you cannot move ahead until you have the results). So if this software bottleneck holds true we should expect slow, intermittent and possibly unpredictable progress.
When you run an AI, its effective intelligence will proportional to how much fast hardware you can give it (e.g. it might run faster, have greater intellectual power or just able to exist in more separate copies doing intellectual work). More effective intelligence, bigger and faster intelligence explosion.
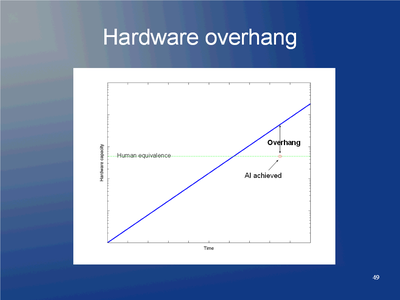
If you are on the hardware side, how much hardware do you believe will be available when the first human level AI occurs? You should expect the first AI to be pretty close to the limits of what researchers can afford: a project running on the future counterpart to Sequoia or the Google servers. There will not be much extra computing power available to run more copies. An intelligence explosion will be bounded by the growth of more hardware.
If you are on the software side, you should expect that hardware has continued to increase after passing "human equivalence". When the AI is finally constructed after all the human and conceptual bottlenecks have passed, hardware will be much better than needed to just run a human-level AI. You have a "hardware overhang" allowing you to run many copies (or fast or big versions) immediately afterwards. A rapid and sharp intelligence explosion is possible.
This leads to our conclusion: if you are an optimist about software, you should expect an early singularity that involves an intelligence explosion that at the start grows "just" as Moore's law (or its successor). If you are a pessimist about software, you should expect a late singularity that is very sharp. It looks like it is hard to coherently argue for a late but smooth singularity.
Discussion
This is a pretty general argument and maybe not too deep. But it does suggest some lines of inquiry and that we might want to consider policy in the near future.
Note that sharp, unpredictable singularities are dangerous. If the breakthrough is simply a matter of the right insights and experiments to finally cohere (after endless disappointing performance over a long time) and then will lead to an intelligence explosion nearly instantly, then most societies will be unprepared, there will be little time to make the AIs docile, there are strong first-mover advantages and incentives to compromise on safety. A recipe for some nasty dynamics.
So, what do we do? One obvious thing is to check this analysis further. We promise to write it up into a full paper, and I think the new programme on technological change we are setting up in Oxford will do a lot more work on looking at the dynamics of performance increases in machine intelligence. It also suggests that if AI doesn't seem to make much progress (but still does have the occasional significant advance), leading us to think the software limit is the key one, then it might be important to ensure that we have institutions (such as researchers recognizing the risk, incentives for constraining the spread and limiting arms races, perhaps even deliberate slowing of Moore's law) in place for an unexpected but late breakthrough that would have a big hardware overhang. But that would be very hard to do - it would almost by definition be unanticipated by most groups, and the incentives are small for building and maintaining extensive protections against something that doesn't seem likely. And who would want to slow down Moore's law?
So if we were to think a late sharp AI singularity was likely, we should either try to remove software limitations to AI progress in the present (presumably very hard, if it was easily doable somebody would have done it) or try to get another kind of singularity going earlier, like a hardware-dominated brain emulation singularity (we can certainly accelerate that one right now by working harder on scanning technology and emulation-related neuroscience). If we are unlucky we might still get stuck on the neuroscience part, and essentially end up with the same software limitation that makes the late AI singularity risky - hardware overhang applies to brain emulations too. Brain emulations might also lead to insights into cognition that triggers AI development (remember, in this scenario it is the insights that are the limiting factor), which in this case would likely be a relatively good thing since we would get early, hardware-limited AI. There is still the docility/friendliness issue, where I think emulation has an advantage over AI, but at least we get more time to try.
October 06, 2010
Crowdsourced surveillance
 Spying on people for fun and profit - I blog about crowdsourced surveillance.
Spying on people for fun and profit - I blog about crowdsourced surveillance.
I wonder if people would be less worried if this was an open source, free project open to anybody to participate in? The integrity aspects would be the same (in fact, likely worse) yet the thing that really seems creepy is that someone makes money from it. But imagine having 4chan's /b/ monitoring the world...
However, we should remember that crowdsourced surveillance is exactly what we should desire for our government and other concentrations of power. They should not resist this if they have nothing to hide.