September 13, 2007
Abstract Network
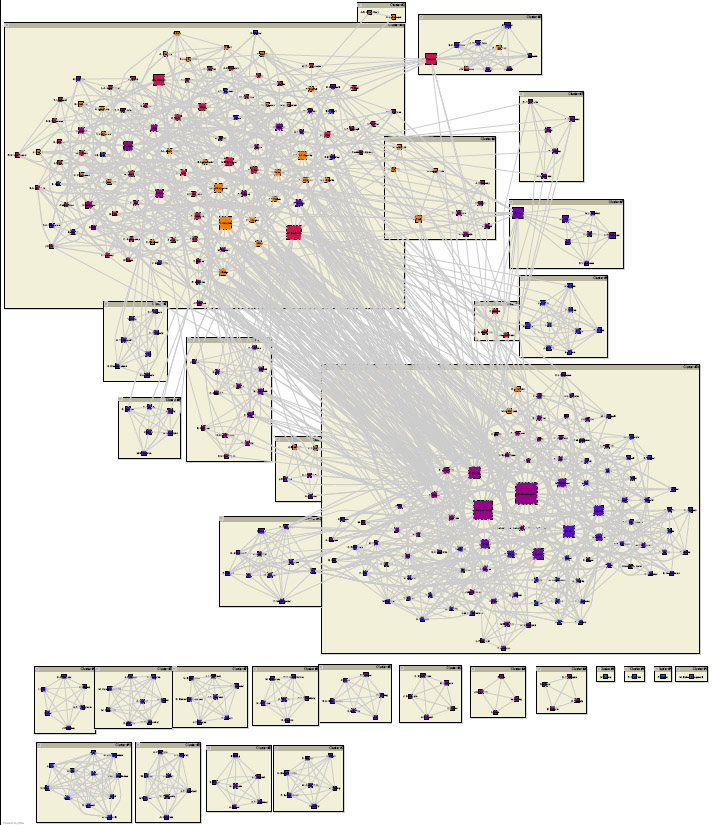 During some easy-to-follow talks at SENS 3 I wrote a small program to find similarities between the abstracts at the conference. The result is this graph (pdf).
During some easy-to-follow talks at SENS 3 I wrote a small program to find similarities between the abstracts at the conference. The result is this graph (pdf).
The basic approach is to add a connection between all authors using the same word. The strength of the connection is 1/k2 where k is the number of authors - common words just add weak connections, distinct similarities produce strong links. People sharing abstracts of course end up strongly linked, but we get subject groups due to text similarities too.
After thresholding the graph I ran Newman and Girvan's community structure algorithm in yEd to cluster the network. The result is pretty nice, showing the big central theme network in the upper left and the "Italian gang" in the lower right, as well as smaller topics and coauthor groups.
I did not use word frequencies here, but an obvious possible improvement would be to use mutual information components like log(P(word,person)/P(word)P(person)) and two-word patterns for higher specificity.
Posted by Anders3 at September 13, 2007 12:18 PM